
canary简单介绍
canary原理
canary是一种用来防护栈溢出的保护机制。其原理是在一个函数的入口处,先从fs/gs寄存器中取出一个4字节(eax)或者8字节,(其长度多半一个字长,rax)的值存到栈上,当函数结束时会检查这个栈上的值是否和存进去的值一致。canary在64位下保护包括rbp rip在内的数据,将其安排到前一个栈帧。 它的生命周期可以分为三个阶段:生成 -> 存储 -> 使用(校验)。
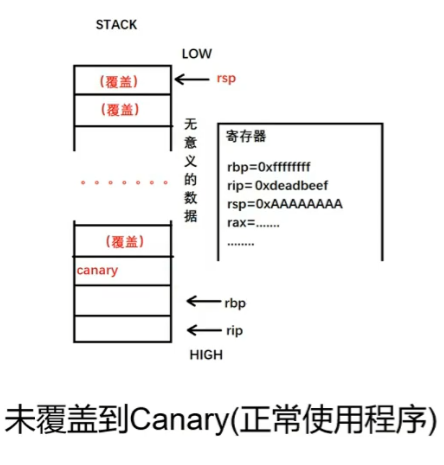
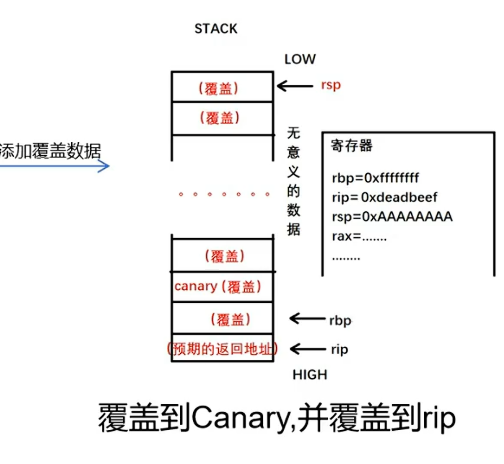
- canary的生成:源头是安全随机
在 Linux 系统上,这个值通常来自 /dev/urandom 这个内核提供的密码学安全伪随机数生成器(CSPRNG)。生成的 Canary 值通常是一个 64 位或 32 位的整数(取决于平台),并且其字节值通常会包含 0x00(空字节)。因为许多导致栈溢出的攻击向量是字符串操作函数(如 strcpy, gets)。这些函数在遇到空字节 0x00 时会停止复制。如果 Canary 中包含空字节,攻击者试图用字符串操作覆盖 Canary 时就会在中途停止,从而无法完整地覆盖和篡改它,导致攻击失败。
- 存储:线程本地存储 (TLS)
生成的 Canary 值存储在哪里?它存储在 线程本地存储 (Thread-Local Storage, TLS) 中。并且每个线程拥有一个。一个程序可能有多个线程,每个线程都有自己的调用栈。如果所有线程共享一个全局的 Canary 值,那么一个线程泄漏了这个值,所有线程的保护就都失效了。为每个线程使用独立的 Canary 值可以隔离风险。
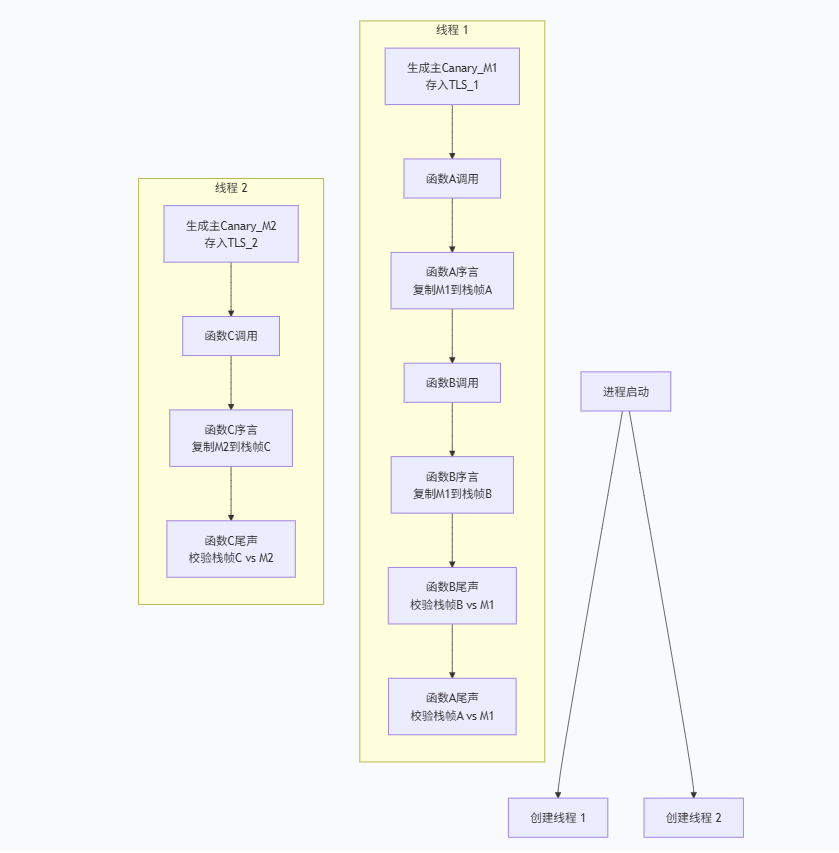
- 访问:通过特殊寄存器(fs)
在 x86-64 架构中,有一个特殊的段寄存器 %fs(或 %gs)用于指向 TLS。Canary 值通常位于 TLS 中的一个固定偏移处。编译器生成的代码会通过类似 %fs:0x28 这样的地址来访问当前线程的 Canary 值。
- 使用与校验:函数序言和尾声
现在,我们看一个函数是如何使用这个值的:
- 函数序言 (Prologue): 当一个被保护的函数开始时,编译器插入的代码会做两件事:从 TLS(如 %fs:0x28)中取出当前线程的 Canary 值。将这个 Canary 值压入到该函数栈帧上的一个特定位置(通常就在保存的基指针和返回地址之前)。
汇编代码看起来像这样:
|
|
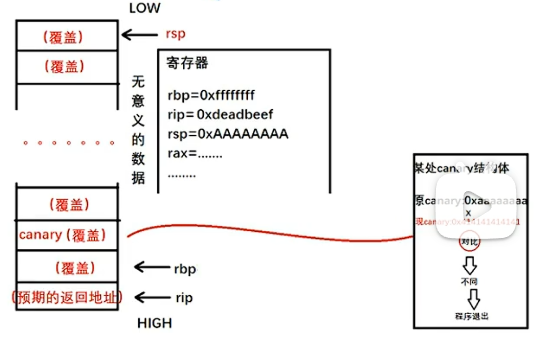
- 函数尾声 (Epilogue): 在函数返回(ret指令)之前,编译器插入的代码会:从栈上之前保存的位置读出 Canary 值。将其与 TLS 中存储的原始 Master Canary 值进行比较。如果两者相等,程序正常返回。如果不相等,说明栈上的 Canary 在函数执行过程中被溢出数据覆盖了,此时会立即跳转到 __stack_chk_fail 函数。
汇编代码看起来像这样:
|
|
__stack_chk_fail 函数会打印出著名的 “*** stack smashing detected ***:
canary初始化源码
security_init.c函数部分源码
|
|
关键宏定义:
|
|
-
解释:
_dl_random:这是一个由内核提供的随机值(通常通过AT_RANDOM AUXV条目传递),作为栈保护canary的种子。 _dl_setup_stack_chk_guard:这个函数处理canary的生成: 使用`_dl_random`作为输入,将最后一个字节设置为0(这是为了阻止C字符串函数覆盖canary值,因为许多字符串漏洞依赖NULL终止符) THREAD_SET_STACK_GUARD:这个宏将生成的canary值存储到当前线程的TLS中: THREAD_SELF:获取当前线程的TLS指针 header.stack_guard是TLS中存储栈保护值的字段位置 使用THREAD_SETMEM将值写入指定位置 _dl_random = NULL:清除随机值源,可能是为了:减少攻击面,防止意外重复使用 -
完整的数据流
内核 → 通过AT_RANDOM AUXV条目提供 _dl_random _dl_setup_stack_chk_guard → 处理随机值,设置最后字节为0 THREAD_SET_STACK_GUARD → 将canary存储到当前线程TLS 编译器 → 在函数 prologue/epilogue 中插入canary检查代码
uintptr_t1数据类型解释
canary报错源码
stack_chk_fail.c源码解析
|
|
- 函数调用
libc_message(): GNU C库内部的函数,用于输出系统消息,2: 第一个参数,通常表示标准错误输出(stderr)
- 格式化字符串
"** %s ***: %s terminatedn": 格式化字符串模板,第一个 %s: 将被 msg 替换,第二个 %s: 将被程序名替换
- 参数
msg: 具体的错误消息字符串
__libc_argv[0]?: "<unknown>"
__libc_argv[0]: 程序的名称(argv[0])
?: "<unknown>": 三元条件运算符,如果程序名为空则使用"<unknown>"
- 实际输出示例
如果 msg = “stack smashing detected”,程序名为 ./test,输出将是:
|
|
canary开启模式
canary主要分为三种(关闭/开启/全开启)
-fstack-protector 和 -fstack-protector-all 都是用于防范栈溢出攻击的保护机制,但它们的保护范围和性能影响有显著区别。
-fstack-protector(默认的栈保护)
这是选择性保护模式。编译器会进行启发式判断,只对包含敏感操作(如字符数组操作)或容易遭受攻击的函数插入保护代码。
保护对象:满足以下条件的函数:
- 使用了 alloca() 函数在栈上动态分配内存的。
- 定义了大于 8 字节的字符数组(char) 或缓冲区(通常是可能发生溢出的源头)的局部变量。
性能:性能开销较小。因为只对一部分“危险”函数进行保护,生成的代码量更小,运行时检查也更少。 安全性:保护范围有限。它可能会错过一些不那么明显但依然存在漏洞的函数。例如,一个使用 int 数组但可能溢出的函数就不会被保护。 用途:这是 GCC 的默认行为(如果启用了栈保护)。在安全性和性能之间提供了一个很好的平衡,适用于大多数情况。
示例:会被 -fstack-protector 保护的函数
|
|
-fstack-protector-all(强栈保护)
这是全面保护模式。编译器会为所有函数插入保护代码,无论其是否看起来存在风险。 保护对象:每一个函数,无论其内部结构如何。
性能:性能开销较大。每个函数在入口和出口都有额外的代码来设置和检查金丝雀值。这会导致生成的二进制文件更大,运行速度稍慢。 安全性:保护范围非常全面。消除了由于编译器启发式判断失误而漏掉漏洞的可能性,提供了更深度的防御。 用途:用于对安全性要求极高的环境,愿意为此牺牲一定的性能。例如,处理不受信任输入的特权程序(sudo, sshd 等)、安全关键型的系统。
示例:会被-fstack-protector-all保护的函数
|
|
其他保护类型
-fstack-protector-strong:这是一个介于 -fstack-protector 和 -fstack-protector-all 之间的选项(GCC 4.9 引入)。它扩展了启发式规则,比 -fstack-protector 保护更多的函数(例如,包含任何类型的数组、有局部变量地址被使用的函数),在不过度增加开销的情况下提供了更好的保护。在许多现代Linux发行版中,这已成为默认的编译选项。
-fno-stack-protector:完全禁用栈保护。
canary检测绕过及利和防护
canary检测
|
|
这是一个canary自动检测方案(不需要手打%p,来自B站某up)
canary绕过方法及其利用
泄露
-
格式化字符串泄露
- 定位Canary:首先需要确定Canary在栈上的偏移位置。在格式化字符串漏洞中,我们可以使用类似 %p %p %p %p … 或 %n$p(n是位置参数)的方式来“窥探”栈上的内容。
- 识别Canary:Canary的值通常以字节 0x00 结尾(这是为了阻止使用字符串操作函数如 strcpy 来泄露它,因为 strcpy 遇到 0x00 会终止)。所以当我们从栈上泄露出一串地址,其中一个值最后两个字节是 00(例如 0x1b2d3c4d5a6b00),它极有可能就是Canary。
- 构造Payload:在后续的溢出中,在覆盖到Canary的位置时,精确地用我们泄露出来的这个值填充,这样函数尾声的校验就会通过,程序不会崩溃,攻击得以继续。
- 在这之中包括另外一种泄露:Canry的最底一个字节设计为b’\x00’,是为了防止put,write,printf登将canary读出。如果利用栈溢出将最低位的b’\x00’覆盖,就可以利用答应函数将canary一致输出,最后再在最低位拼接上 b’\x00’就可以得到canary。
-
爆破(fork)
原理:爆破(Brute-Force)Canary(适用于fork服务)这种方法常用于网络服务,这些服务使用 fork() 模式来处理客户端连接(例如,一个主进程监听,每来一个连接就fork一个子进程来处理)。
-
进程内存镜像复制(Fork):fork() 创建的子进程会完整地复制父进程的内存空间。这意味着每个连接对应的子进程,其Canary值是完全相同的。
-
逐字节爆破:Canary通常是一个4字节(32位)或8字节(64位)的值,但其最后一个字节固定为 0x00。所以我们只需要爆破前面的3或7个字节。攻击者可以多次连接服务,每次尝试爆破Canary的一个字节。从最低位字节(LSB)开始(注意小端序,内存中第一个字节是最低位)。利用栈溢出,溢出到canary位置,从低位到高位 逐次覆盖掉canary的4个字节(一位无法绕过低位字节堆高位进行爆破,所以必须从低到高),且要求canary不能变化,绕过重开程序canary变化,就不适用爆破了。例如,对于一个64位Canary 0x00 0xab 0xcd 0xef 0x12 0x34 0x56 0x78,爆破顺序是从 0x78 开始,然后是 0x56,依此类推,直到 0xab(0x00 不用爆,直接填)。利用崩溃反馈:攻击者发送一个精心构造的payload:[填充缓冲区的垃圾数据] + [已猜解的部分Canary] + [尝试爆破的下一个字节]。如果这个字节猜对了,Canary校验通过,程序不会崩溃,可能会因为后续的返回地址错误而表现出其他行为(比如连接意外断开或无响应)。如果猜错了,__stack_chk_fail 会被触发,子进程立刻崩溃。攻击者通过观察连接是否“立即断开”(崩溃)来判断字节是否猜对。重复过程:从一个字节开始,逐步猜出整个Canary。因为每次猜一个字节(256种可能性),所以最多只需要 7 * 256 = 1792 次尝试,这在计算上是完全可行的。
-
基于每次连接fork出的新进程,其Canary都和上一次一样。上次猜对的字节,这次依然有效,所以可以基于已知字节继续猜下一个。
-
-
连带输出
这种方法利用了格式化字符串和程序逻辑的结合。
原理漏洞组合:程序存在两个漏洞:
- 一个栈溢出漏洞(用于覆盖Canary和返回地址)。
- 一个格式化字符串漏洞(用于泄露信息)。
触发流程:
- 攻击者首先构造一个不完全的溢出Payload。这个Payload会覆盖Canary之后的一部分栈空间,但故意不覆盖Canary本身(或者用可能正确的值覆盖,期望它能通过),而是去覆盖一个即将被格式化字符串函数使用的参数(比如格式化字符串的指针本身,或者一个指向指针的指针)。
- 程序执行流继续,并没有因为栈溢出而崩溃(因为Canary没被破坏或碰巧猜对了)。
- 程序随后执行到存在格式化字符串漏洞的代码(例如 printf(user_input))。但此时,栈上的状态已经被之前的溢出Payload修改了。
- 被修改的栈空间,恰好控制了格式化字符串函数的一个或多个参数。攻击者可以精心设计,让这个格式化字符串(例如 %n$p)去读取并输出栈上任意位置的值,其中就包括真正的Canary。
- 程序将这个Canary值打印(输出) 给攻击者。
- 完成攻击:攻击者拿到Canary后,就可以在第二次交互中,构造一个完整的、包含正确Canary的ROP链Payload,最终实现利用。 这种方法的核心是“用一次不完美的溢出来为格式化字符串漏洞配置环境,从而泄露关键信息,为第二次的攻击做准备”。
劫持_stack_chk_fail
-
函数行为
检测到栈溢出:如果攻击者通过栈溢出(例如,缓冲区溢出)覆盖了函数的返回地址,那么很可能会同时覆盖这个金丝雀值。函数在返回前检查发现金丝雀值不匹配,就会调用
__stack_chk_fail函数。- 行为:
__stack_chk_fail的默认实现是打印一条错误信息(如 “** stack smashing detected **")并立即终止程序(通常通过 abort())。
- 行为:
-
劫持
__stack_chk_fail目的- 获取程序控制流:在栈溢出攻击中,攻击者可能无法精确地控制金丝雀值。如果触发了栈保护,程序会崩溃,攻击失败。通过劫持
__stack_chk_fail,攻击者可以将崩溃转化为机会:不让程序简单地退出,而是让它跳转到攻击者控制的代码(Shellcode)。 - 信息泄露:在某些高级攻击中(如通过覆盖局部变量实现的部分写),可能故意触发
__stack_chk_fail来泄露内存信息或其他数据。 - 绕过保护:这是最直接的动机。通过控制
__stack_chk_fail的行为,攻击者实质上禁用或绕过了栈保护机制,使得传统的栈溢出攻击得以继续。
- 获取程序控制流:在栈溢出攻击中,攻击者可能无法精确地控制金丝雀值。如果触发了栈保护,程序会崩溃,攻击失败。通过劫持
-
劫持
__stack_chk_fail方法覆盖程序运行时使用的
__stack_chk_fail函数的地址。主要有以下几种方法:-
修改 GOT 表(全局偏移表)这通常是 基于二进制漏洞利用 的首选方法,因为它不需要源代码。 在 Linux 等使用 ELF 格式的系统中,共享库函数(如
__stack_chk_fail,它位于 libc 中)的地址存储在名为 GOT 的数据段中。程序在调用__stack_chk_fail时,实际上是通过 GOT 表进行间接跳转。使用 objdump -R ./binary 或 readelf -r ./binary 命令查找__stack_chk_fail在 GOT 中的地址。你会看到一条记录,显示__stack_chk_fail@got.plt的地址(例如 0x804a00c)。 找到你的 Shellcode 在内存中的地址(例如 0xffffd100)。 -
利用漏洞:通过栈溢出或其他内存破坏漏洞(如格式化字符串漏洞),将 GOT 表中
__stack_chk_fail的条目覆盖为你想要的地址(例如你的 Shellcode 地址)。 -
触发检查:故意造成一个栈溢出,触发栈保护检查。程序会照常去调用
__stack_chk_fail,但由于 GOT 表被修改,它实际上会跳转到你的 Shellcode 地址,从而执行你的代码。
-
SSP Leak(在2.27及以上版本已经失效)
防御措施
现代系统针对这种劫持技术也有相应的防御措施:
RELRO(Relocations Read-Only)是一种用于增强 Linux 下 ELF 二进制文件安全性的安全加固技术。它的主要目标是保护 ELF 二进制文件中的某些关键数据结构(主要是动态链接相关的部分)在运行时不被恶意修改,从而防止一系列利用漏洞(如全局偏移表GOT覆盖攻击)的攻击手段。 要理解 RELRO,首先要理解它要解决的安全问题:GOT 覆盖攻击
-
动态链接:Linux 上的程序为了节省内存,通常会动态链接到像 libc 这样的共享库。这意味着程序在运行时才知道这些库函数的实际内存地址。 全局偏移表(GOT):为了实现动态链接,编译器会创建一个叫做 GOT 的数据结构。它可以被理解为一个“函数地址查询表”。当程序第一次调用一个共享库函数(如 printf)时,动态链接器会找到 printf 的真实地址,并将其写入到 GOT 中对应的条目。之后每次调用 printf,程序就直接从 GOT 中读取地址并跳转过去。 安全问题:GOT 表是可写的。这是一个致命的安全隐患。如果攻击者通过一个漏洞(如栈缓冲区溢出或格式化字符串漏洞)能够向任意内存地址写入数据,他们就可以: 找到要攻击的函数的 GOT 表地址(例如 system 或 __stack_chk_fail 的 GOT 条目)。这个条目覆盖为他们想要的地址(例如 /bin/sh 的地址,或者他们自己的 Shellcode 地址)。当下一次程序调用这个被劫持的函数时,控制流就会跳转到攻击者指定的地址,从而完成攻击。RELRO 就是为了解决这个“GOT 表可写”的问题而诞生的。
-
RELRO 有两种级别,提供不同强度的保护:
- 部分 RELRO(Partial RELRO) -Wl,-z,relro
这是 GCC 的默认编译选项(除非你用 -Wl,-z,norelro 显式关闭)。
- 重排序段:它让链接器重新排列 ELF 文件中的各个数据段(section),将 ELF 内部的数据段(如 .got, .dtors, .ctors 等)放在程序的数据段(如 .data 和 .bss)之前。这可以防止一些基于全局变量溢出的攻击,因为溢出会向后覆盖,而关键数据段在前面,不会被覆盖到。
- 标记只读:它将 GOT 表 之前的 .got.plt 部分(包含过程链接表PLT使用的GOT条目)标记为只读。但注意,完整的 GOT 表(.got)仍然是可写的,因为延迟绑定(lazy binding)机制需要写入它。
- 安全性:部分 RELRO 无法防止针对 GOT 表的覆盖攻击,因为 .got 仍然可写。它主要缓解的是其他一些不那么常见的攻击向量。
- 完全 RELRO(Full RELRO) -Wl,-z,relro,-z,now这是更严格、更安全的模式。
- 它包含了部分 RELRO 的所有保护措施。它禁用了延迟绑定(lazy binding)。程序在启动阶段,由动态链接器 (ld-linux.so) 一次性解析并填充所有外部函数的真实地址到 GOT 表中。
- 在完成所有符号解析后,将整个 GOT 表(包括 .got 和 .got.plt)标记为只读。
- 安全性:完全 RELRO 可以有效防止 GOT 覆盖攻击。因为攻击者再也无法向 GOT 表写入任何数据。
- 启动时间变长:因为所有动态链接符号都在程序开始时解析,而不是在第一次调用时解析,这导致程序的启动时间稍微增加。对于依赖大量共享库的大型程序(如 Firefox,LibreOffice),这个影响可能更明显。
- 内存占用:所有符号都被立即解析,可能会稍微增加初始内存占用。
- 部分 RELRO(Partial RELRO) -Wl,-z,relro
这是 GCC 的默认编译选项(除非你用 -Wl,-z,norelro 显式关闭)。
-
一篇关于ASLR的论文
-
这是无符号整数类型,具有以下关键特性:
- 类型定义:在 <stdint.h> 头文件中定义
- 用途:能够安全地存储指针值的无符号整数类型
- 保证:任何有效的(void*)指针都可以转换为uintptr_t,然后再转换回(void*)而不会丢失信息
- 平台兼容性:指针大小随架构变化(32位 vs 64位),uintptr_t 会自动匹配当前平台的指针大小
- 整数运算:canary值需要进行位操作(如设置最后字节为0),使用整数类型便于进行位运算,但需要保证与指针相同的位宽